Você está interessado no tópico de Processamento de Linguagem Natural ou PNL . Então você está exatamente aqui. Neste artigo você obterá todas as informações importantes sobre processamento de linguagem natural .
O que é Processamento de Linguagem Natural?
O Processamento de Linguagem Natural (NLP) é um processo para analisar e representar automaticamente a linguagem humana. O Processamento de Linguagem Natural tenta capturar a linguagem natural e processá-la de maneira baseada em computador usando regras e algoritmos.
Em outras palavras, o Processamento de Linguagem Natural também NLP é o processo de análise de texto e linguagem humana fazendo relações entre palavras, entendendo o significado dessas palavras e obtendo uma melhor compreensão do significado das palavras para obter informações, conhecimento, ou novos para gerar texto
Quais formas de aprendizado de máquina o processamento de linguagem natural usa?
O processamento de linguagem natural depende de vários tipos de aprendizado de máquina , como aprendizado de máquina supervisionado e aprendizado de máquina não supervisionado, para reconhecer o conteúdo e a estrutura de textos e linguagem falada com base em modelos estatísticos e análises de espaço vetorial . Abordagens de PNL mais recentes também lidam com métodos para geração de texto e rotulagem (marcação) por meio de aprendizado de reforço (aprendizado de reforço) por meio de aprendizado de máquina supervisionado semi ou fraco .
Como funciona o processamento de linguagem natural?
Em geral, a funcionalidade do NLP gobe pode ser dividida nas seguintes etapas do processo:
- fornecimento de dados
- preparação de dados
- análise de texto
- enriquecimento de texto
O processo tradicionalmente começa com o fornecimento de dados por meio de um corpus de texto, que consiste em vários documentos. Estes consistem em pelo menos uma palavra, mas geralmente várias frases. Um corpus de texto seria, por exemplo, todos os documentos relevantes sobre o assunto de SEO . Os documentos individuais consistem em capítulos, parágrafos e frases. As sentenças são então divididas em tokens individuais por sentença. Aqui está um exemplo de um post de glossário sobre SEO :
Search Engine Optimization ( SEO ) é um método de marketing online paramelhorarcapacidadede localização nosmotores de busca . AsiglaSEOsignifica Search Engine Optimization . Nosúltimosanos, umsegundo significadoaceitação com a otimização da experiência de pesquisa . Naotimização de mecanismo de pesquisaclássicaédistinçãoentre e SEO fora da página .
Os tokens individuais permanecem no contexto das sentenças para que as relações entre eles sejam preservadas. Isso preserva a relação semântica de parágrafos, sentenças e tokens. Na etapa do processo de preparação de dados , os tokens individuais são fornecidos com rótulos ou anotações.
O documento assim anotado serve de base para outras medidas preparatórias, como incorporação de texto ou reconhecimento e interpretação de entidades (reconhecimento de entidade).
Então, na próxima etapa, os modelos podem ser aplicados aos documentos preparados. Esses modelos de linguagem são aprendidos com base em aprendizado de máquina ou dados de treinamento. Nesta etapa do processo, os dados de treinamento são divididos em tokens, atribuídos a uma classe lexical e as estruturas das sentenças são determinadas. Na análise semântica final, as entidades são identificadas e anotadas de acordo com seu significado.
Os principais componentes do NLP são tokenização , marcação de parte da fala , lematização , dependências de palavras ( análise de dependência ), rotulagem de análise , extração de entidades nomeadas ( reconhecimento de entidade nomeada ), pontuação de saliência , análise de sentimento , categorização , classificação de texto , extração de conteúdo tipos eIdentificação de um significado implícito devido à estrutura .
- Tokenização : Tokenização é o processo de quebrar uma frase em termos diferentes.
- Rotulagem de palavras de acordo com as partes do discurso: A rotulagem das partes do discurso classifica as palavras de acordo com as partes do discurso, como sujeito, objeto, predicado, adjetivo…
- Dependências de palavras: as dependências de palavras criam relacionamentos entre palavras com base em regras gramaticais. Esse processo também mapeia “saltos” entre as palavras.

Exemplo de marcação de parte da fala e análise de dependência, fonte: Explosion.ai Demo
- Lematização: A lematização determina se uma palavra tem formas diferentes e normaliza variações para a forma base. Por exemplo, a forma básica dos animais é animal, ou jogo lúdico.
- Rótulos de análise: o rótulo classifica a dependência ou o tipo de relacionamento entre duas palavras que estão ligadas por uma dependência.
- Análise e Extração de Entidades Nomeadas: Devemos estar familiarizados com este aspecto das postagens anteriores. Isso tenta identificar palavras com um significado “conhecido” e atribuir classes a tipos de entidade . Em geral, entidades nomeadas são pessoas, lugares e coisas (substantivos). As entidades também podem conter nomes de produtos. Estas são geralmente as palavras que acionam um painel de conhecimento . No entanto, os termos que não acionam seu próprio painel de conhecimento também podem ser entidades . Mais sobre isso no artigo O que é uma entidade? O que são entidades?

Exemplo de análise de entidade usando a API de processamento de linguagem natural do Google.
- Pontuação de saliência: A saliência determina a intensidade com que um texto lida com um tópico. Isso é determinado em PNL com base nas chamadas palavras indicadoras. Em geral, a notoriedade é determinada pela citação de palavras na web e pelas relações entre entidades em bancos de dados como Wikipedia e Freebase. O Google provavelmente também aplica esse diagrama de ligação à extração de entidades em documentos para determinar esses relacionamentos de palavras. SEOs experientes estão familiarizados com um procedimento semelhante da análise TF-IDF.
- Análise de Sentimentos: Em resumo, é uma avaliação da opinião (visão ou atitude) expressa em um artigo sobre as entidades abordadas no texto.
- Categorização de assunto: No nível macro, o NLP classifica o texto em categorias de assunto. A categorização de tópicos ajuda a determinar, em geral, sobre o que é o texto.
- Classificação e função do texto: a PNL pode ir além e determinar a função pretendida ou o propósito do conteúdo.
- Extração de tipo de conteúdo: o Google pode usar padrões estruturais ou contexto para determinar o tipo de conteúdo de um determinado trecho de texto sem identificá-lo como dados estruturados. O HTML, a formatação do texto e o tipo de dados do texto (data, local, URL etc.) podem ser usados para entender o texto sem marcações adicionais. Esse processo permite que o Google determine se o texto é um evento, uma receita, produto ou outro tipo de conteúdo sem a necessidade de usar marcação.
- Identificação de um significado implícito com base na estrutura: A formatação de um corpo de texto pode alterar seu significado implícito. Títulos, quebras de linha, listas e proximidade fornecem uma compreensão secundária do texto. Por exemplo, se o texto aparecer em uma lista ordenada por HTML ou em uma série de cabeçalhos precedidos por números, provavelmente é uma operação ou classificação. A estrutura é definida não apenas por tags HTML, mas também pelo tamanho/peso da fonte visual e proximidade quando renderizada.
Alguns desses elementos centrais do processamento de linguagem natural devem ser familiares para você nas postagens anteriores desta série de artigos, como a extração de entidades nomeadas ou a identificação de significado implícito com base em elementos de estrutura.
A API de processamento de linguagem natural, que gostaria de discutir abaixo, mostra que o Google já domina muitos desses processos.
Áreas de aplicação para processamento de linguagem natural
O processamento de linguagem natural é usado de muitas maneiras diferentes, incluindo reconhecimento de fala, síntese de conversão de texto em fala, tradução automática, resposta a perguntas, resumo, análise de sentimento e muito mais. Ele tem uso em muitos campos, como saúde, educação, finanças, direito, atendimento ao cliente, mecanismos de pesquisa e governo.
O processamento de linguagem natural pode ser usado para as seguintes áreas de aplicação:
- Reconhecimento de fala (texto para fala e fala para texto)
- Segmentação da fala previamente capturada em palavras, sentenças e frases individuais.
- Reconhecer as formas básicas das palavras e adquirir informações gramaticais
- Reconhecer as funções de palavras individuais na frase (sujeito, verbo, objeto, artigo, etc.)
- Extração do significado de frases e partes de frases ou frases como frases adjetivas (por exemplo, muito longas), frases preposicionais (por exemplo, para o rio) ou frases substantivas (por exemplo, a festa muito longa)
- Reconhecer contextos de sentenças, relacionamentos de sentenças e entidades.
- Reconhecendo sentimentos em fala e texto e em torno de entidades.
- Saída de texto e fala
O processamento de linguagem natural pode ser usado para análise de texto linguístico , análise de humor e opinião ( análise de sentimento ), traduções , bem como para assistentes de linguagem , chatbots e os sistemas subjacentes de perguntas e respostas .
NLP vs. NLU: Qual é a diferença entre Processamento de Linguagem Natural e Entendimento de Linguagem Natural
Natural Language Understanding ( NLU) é uma subárea do Natural Language Processing .
Com nomes semelhantes, ambos os conceitos lidam com a relação entre a linguagem natural (como falamos como humanos, não o que os computadores entendem) e a inteligência artificial.
Eles compartilham o objetivo comum de entender os conceitos representados em dados não estruturados, como linguagem, melhor do que dados estruturados, como estatísticas, ações, etc. Para esse fim, NLP e NLU são opostos de muitas outras técnicas de mineração de dados. Mas é aí que as comparações param: NLU e NLP não são iguais.
A PNL inclui duas áreas principais de trabalho: Compreensão de Linguagem Natural (NLU) e Geração de Linguagem Natural (NLG). Natural Language Generation (NLG) refere-se a qualquer tecnologia que permite que os computadores gerem texto em linguagem humana. Os sistemas NLG podem ser usados para uma variedade de finalidades, incluindo resumo, gerenciamento de diálogo, resposta a perguntas e chatbots.
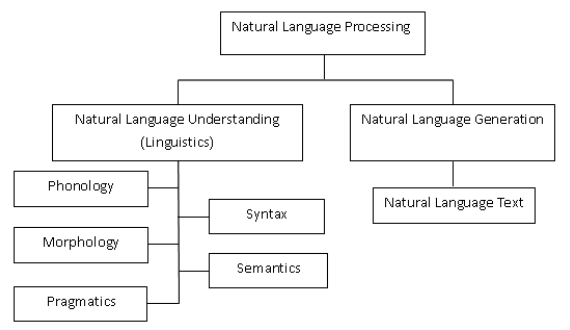
Compreensão da linguagem natural é uma tecnologia que permite que os computadores entendam a linguagem humana.
Como um subtópico da PNL, a NLU é um ingrediente essencial para o sucesso da PNL. NLU tem um propósito mais restrito e se concentra principalmente na compreensão de leitura de máquina: fazer com que o computador entenda o que um corpo de texto realmente significa.
A compreensão da linguagem natural pode ser aplicada a uma variedade de processos, por ex. B. categorização de texto, coleta de mensagens, arquivamento de trechos individuais de texto e, em escala maior, análise de conteúdo.
Os exemplos do mundo real de NLUs variam de pequenas tarefas, como emitir comandos curtos para entender o texto, até redirecionar um e-mail para a pessoa certa com base na sintaxe básica e em um léxico de tamanho razoável. Um esforço muito mais complexo pode ser capturar totalmente artigos de notícias ou nuances de significado em poesia ou romances.
O NLU é melhor visto como o primeiro passo para alcançar o NLP: antes que uma máquina possa processar uma linguagem, ela deve primeiro entendê-la.
Uma boa maneira de entender a diferença entre PNL e NLU? É Compreensão de Linguagem Natural quando se refere apenas à capacidade de uma máquina de entender nossa linguagem e o que dizemos. Quando se trata de mais do que isso, como tomar decisões com base no texto, responder ao conteúdo como em um chatbot conversando com um humano, é provável que o conceito mais amplo de processamento de linguagem natural esteja envolvido.
Uso de processamento de linguagem natural em mecanismos de busca
Acho que, quando se trata da Pesquisa do Google, o processamento de linguagem natural é usado principalmente nas seguintes áreas:
- Interpretação de consultas de pesquisa e documentos (Rankbrain, BERT & MUM )
- Classificação de assunto e finalidade dos documentos
- Análise de entidade em documentos, consultas de pesquisa e postagens de mídia social
- Para snippets em destaque e pesquisa por voz
- Interpretação do conteúdo do vídeo
- Ampliação e melhoria do Knowledge Graph
O processamento de linguagem natural é a principal metodologia de identificação de entidades
Como no artigo Como o Google pode identificar e interpretar entidades de conteúdo não estruturado? explicado, o processamento de linguagem natural atualmente desempenha o papel mais importante para o Google na identificação de entidades e seus significados.
A prática mostra, no entanto, que o Google até agora só usou informações não estruturadas de forma muito limitada, pelo menos no que diz respeito à exibição nos painéis de conhecimento. Encontramos as primeiras aplicações práticas para mineração de dados a partir de dados não estruturados nos trechos em destaque, embora isso pareça mais com o uso direto do processamento de linguagem natural sem incluir o gráfico de conhecimento .
Mesmo com entidades não registradas anteriormente no Knowledge Graph, o Google atualmente trabalha apenas com NLP para identificá-las, independentemente do Knowledge Graph. O processamento de linguagem natural faz um bom trabalho ao identificar entidades e classificá-las por tópico. No entanto, isso apenas garantiria o critério de completude e atualidade. No entanto, a PNL sozinha não garante a correção.
Acho que o Google já é bastante bom na área de processamento de linguagem natural, mas ainda não alcançou resultados satisfatórios ao avaliar as informações extraídas automaticamente no que diz respeito à correção. Essa provavelmente será a razão pela qual o Google ainda é cauteloso quando se trata de posicionamento direto nas SERPs .
tópicos relacionados
- aprendizado de máquina
- inteligência artificial
- mineração de texto
- ciência de dados
- análise semântica
- extração de informações
- gerenciamento de informações
Perguntas frequentes sobre processamento de linguagem natural
O que significa processamento de linguagem natural
O Processamento de Linguagem Natural (NLP) é um processo para analisar e representar automaticamente a linguagem humana. O Processamento de Linguagem Natural tenta capturar a linguagem natural e processá-la de maneira baseada em computador usando regras e algoritmos. O NLP usa vários tipos de aprendizado de máquina supervisionado e aprendizado de máquina não supervisionado para reconhecer o conteúdo e a estrutura de textos e linguagem falada com base em modelos estatísticos e análise de espaço vetorial.
Como funciona o processamento de linguagem natural?
Em geral, o funcionamento do NLP gobe pode ser dividido nas seguintes etapas do processo: – Fornecimento de dados – Preparação de dados – Análise de texto – Enriquecimento de texto Mais sobre isso neste artigo.
Onde a PNL é usada?
O processamento de linguagem natural pode ser usado para as seguintes áreas de aplicação: – Reconhecimento de fala (texto para fala e fala para texto) – Segmentação de linguagem previamente gravada em palavras, sentenças e frases individuais. – Reconhecer as formas básicas das palavras e – – – Capturar informações gramaticais – Reconhecer as funções de palavras individuais na frase (sujeito, verbo, objeto, artigo, etc.) – Extrair o significado de frases e partes de frases ou frases como frases adjetivas (por exemplo, muito longas), frases preposicionais (por exemplo, para o rio) ou frases substantivas (por exemplo, para uma festa longa) – Reconhecer contextos de frases, relacionamentos e entidades de frases.